search-engine-security-breach
Search engine information retrieval with Lucene.
View the Project on GitHub yeexunwei/search-engine-security-breach
search-engine-security-breach
Develop a search engine with Lucene model. Results returned are ranked using tf-idf score. Users provide relevance feedback to improve the effectiveness of the information retrieved.
Project Objective
- To develop a system with information retrieval function implementing Lucene.
- To rank search result based tf-idf score.
- To implement a ranking function based on relevance feedback to improve the effectiveness of the information that will be retrieved.
Methods Used
- Indexing
- Text and Query Operation
- Relevance Feedback
Technologies
- Python
- Python whoosh, pandas, flask, json
- HTML, CSS
Project Description
forms.py- flask form classgraph.ipynb- working notebook to determine calculation for relevance feedbacklucene.py- includes stemming, indexing, tokenising, calculate search score and return search resultswebapp.py- final working flask app to handle route for home, search, result and add rating
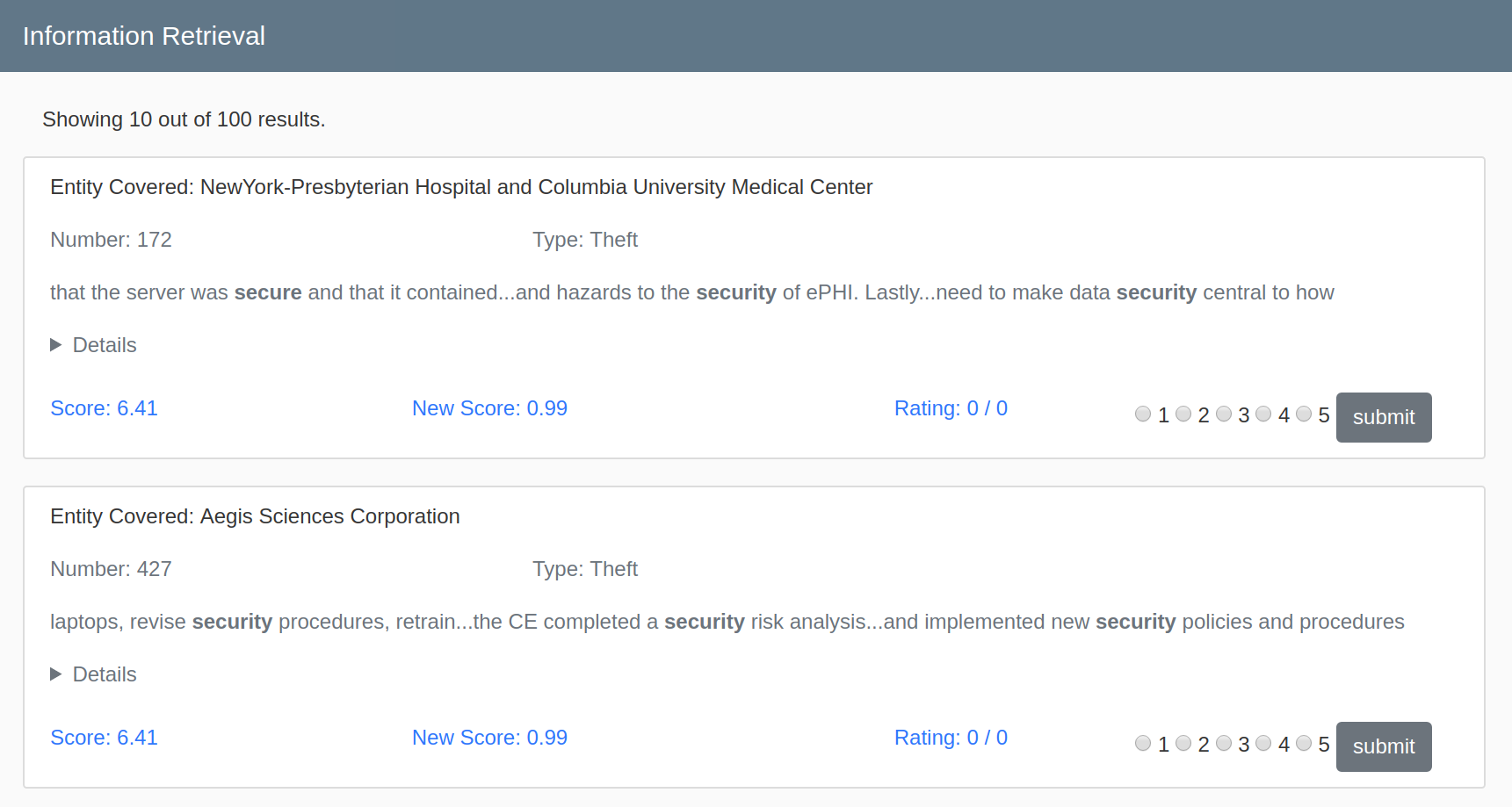
In this Information Retrieval system we used tf-idf model which stands for term frequency inverse document frequency, is a scoring measure widely used in information retrieval (IR) or summarization. TF-IDF is intended to reflect how relevant a term is in a given document. The intuition behind it is that if a word occurs multiple times in a document, we should boost its relevance as it should be more meaningful than other words that appear fewer times (TF). At the same time, if a word occurs many times in a document but also along many other documents, maybe it is because this word is just a frequent word; not because it was relevant or meaningful (IDF). The importance increases proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus.
A ranking function will be implemented to rank query terms by user using Lucene library. Tf-idf score will calculate the term weightage for given user query and documents. Initial ranking of the documents is based on tf-idf weightage.
Relevance Feedback
With rating given by user, the system generates the next set of relevant information. Rating option of one to five is provided for user according to queries. Three steps of calculation:
- Calculate average rating.
For each document calculate the average rating by all users based on query. - Get the greatest number of user rating.
For normalization purpose get the max number of user rating. - Calculate new score.
Log function is used to normalise the rating score and number of user rating. A constant ten is added to avoid negative numbers and zero. A weighted score of tf-idf score (0.9) and rating score (0.1) is calculated.
Data source from Kaggle.
Process Flow
- frontend development
- text processing/cleaning
- indexing
- revelance feedback score calculation
- writeup/reporting
Getting Started
Prerequisites
# flask
pip install flask
# whoosh
pip install whoosh
Deployment
export FLASK_APP=webapp.py
flask run
Running on:
- http://127.0.0.1:5000/search/security
- http://127.0.0.1:5000/api/search?term=breach